I have just blown 4 – 5 hours on this “feature” of PHP and I thought someone else would care to know.
You can’t use numeric keys for sessions in php! Continue reading
I have just blown 4 – 5 hours on this “feature” of PHP and I thought someone else would care to know.
You can’t use numeric keys for sessions in php! Continue reading
Life is too short not to have garbage collection …
– Awesome quote from a developer Jon Cooper who I was talking with at SxSWi.
He was talking about writing code in .NET and coding speed reliant modules in C++ or C.

Panelists
Kevin Rose | Digg
Cal Hendersen | Flickr
Joe Stump | Digg
Chris Lea | Media Temple
Garrett Camp Stumble Upon
Matt Mullenweg | WordPress
{Discussion: Kevin seems to be moderating}
I got around to reading this very insightful piece about truly beautiful code on coding horror today.
In it, Jeff Atwood talks about the problem with the book Beautiful Code, which is that it actually talks about code and not the ideas behind the code.
To put it succinctly in Jeff’s words … Continue reading
“We have to reinvent the wheel every once in a while, not because we need a lot of wheels; but because we need a lot of inventors.”
– Bruce Joyce
I wrote about my experience writing a site crawler in php in an earlier post, and I’m going to use some of the background there to make my point here. So it might help to go read it if you haven’t already.
[Google’s crawler [Googlebot] isn’t that sophisticated/writing a crawler in php]
From my casual observation of the way Googlebot crawls some of the sites I work on, I have reached the conclusion that it works in much the same way that a crawler I wrote a year ago worked.
Google bot goes page to page, gathering links from your page and tacking them onto the current url that it is at, right then. So why do query strings give it such a problem? Continue reading
I spent a lot of time early last year, trying to write a crawler in php (I know, I know).
It was supposed to sit on the server and when so that when you went to the url, it’d generate a google sitemap for your entire site.
What I found out was that writing a good crawler is very hard work. Not because of the recursion involved, but because of the infinite ways link tags appear.
Now Google has validated my experience (more on this in a second).
I consider myself a power user of windows xp, so why haven’t I upgraded from winamp 5.35 to winamp 5.52?
After all, every single time I start winamp it bugs me to.
The answer is simple … Its because I’m lazy.
I’m not going to go to winamp.com, try to figure out which version to download and then actually install it over again, just so winamp runs exactly the same as it did before! No way.
But, if the program went out there got the update and installed it for me … I wouldn’t object.
Firefox does this right.
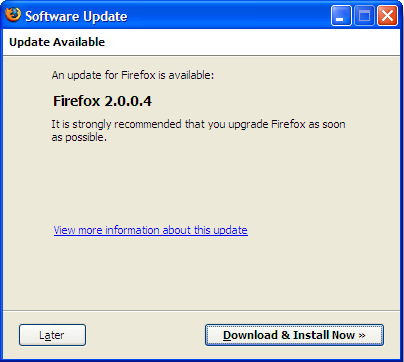
When an update is available, it goes out and finds it for me. If I okay it, it installs the update for me and restarts my browser, putting me back viewing the page I was looking at before … like nothing happened. All I have to do is hit “Download & Install Now”. How easy is that?
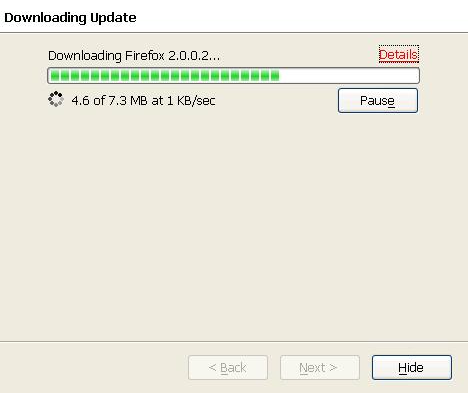
Nag screens/prompts/dialogs are very annoying. My natural instinct is to close them and get on with my life.
In that scenario, everybody loses.
So if you write software, you should strive to have it update automatically, if you possibly can. That would definitely be a selling point for me as your customer. (Hear that Blumenthals software?)
PS: Most software (including wordpress) does require you to go download and install the newest versions. Since automatically updating software is so rare it could be a killer feature if you incorporated it into your software.
Here’s some excerpts from DHH’s post and comments yesterday on 37 signals
- The short answer is that we don’t document our projects. At least not in the traditional sense of writing a tome that exists outside of the code base that somebody new to a project would go read …
- Further more, I don’t really find it necessary for the kind of work that we do. Our biggest product, Basecamp, is about 10,000 lines of code. That really isn’t a whole lot in the grand scheme of things. Everything we do is build is also using Ruby on Rails, which means that most Rails programmers would know their way around our applications straight away. It’s the same conventions and patterns used throughout.
- Finally, we write our application in a wonderfully expressive and succinct programming language like Ruby that leads itself very well to a programming style like the one Kent Beck preaches in Smalltalk Best Practice Patterns. Keep your methods short and expressive. On average, our models have methods just four lines long. Adding documentation to a method should usually only be done when you’re doing something non-obvious that can’t be rewritten in an obvious way.
- [comment] Wim, yes there’s RDoc. I just generally don’t use it for projects. When methods are only an average of 4 lines long written in a language like Ruby, it’s often faster and better to merely browse the code base rather than rely on explicit commenting.
Keep in mind that I’m no Ruby on Rails genius, and from the little I’ve done I can see where DHH is going with this. But I’ve always thought that this argument of a language being so succinct and clear that you don’t have to write comments is just a bit silly for a couple of reasons.
Note, that I’m not of the school of thought of commenting just for the sake of it, like I’ve heard some “blub programmers” do. However, I do think that you should always be thinking of other developers when you code and if commenting can get them to a point where they can modify your code in 1 minute instead of a minute and a half … then you should comment.
In the end, I guess its a bit unfair to criticize DHH, because its not clear that he doesn’t comment his code much … though its easy to infer that. I just know from my experience that people who say things like he says have a tendency to have 3 lines of comments in some piece of code 500 lines long.
But if you’re a “rockstar developer, I guess everyone has to dance to your tune, wherever you are right?
I was trying to take advantage of PHP5’s new auto_prepend_file directive today, by using the php_value directive to set it in a .htaccess file. But as soon as I did that, my cheerfully running application puked and died, with the familiar message.
“Internal Server Error
The server encountered an internal error or misconfiguration and was unable to complete your request”
I had seen this behavior before, when I was writing an app for a client a few months ago, but I hadn’t had time to investigate it. Today I decided to go a-googling and I promptly found my answer …
Those are Apache directives, but in CGI mode Apache calls the php binary, which turn reads php.ini. Since the binary doesn’t read httpd.conf it has no effect on PHP. As PHP isn’t loaded into Apache, Apache doesn’t know what to do with the directives and borks.
Ian Bickings’s “What PHP Deployment gets right”
This is a wonderfully written article on how PHP works, and the funny thing is that Ian seems to be more of a Python guy than anything. Needless to say, I learned a few things from reading this … Continue reading
Although I haven’t done as much work with Rails as I’d like, I follow it very closely because I like the language and the platform, plus I’m sure to write a web application in it in the next month or two.
In the last few weeks, though, there have been some interesting developments in the ROR space. Ace programmer Zed Shaw fired two broadsides against the Rails community a few weeks back titled Rails is a ghetto. [aside: there is this very interesting O’Reilly interview with Zed that might help you understand his accomplishments with Ruby]
Its an interesting read, albeit unprofessional and rather profane. Continue reading
 I worked as a developer with a Search Engine Optimization firm for some time, where I learned that some shady companies are able to buy domain names that you search for online.
I worked as a developer with a Search Engine Optimization firm for some time, where I learned that some shady companies are able to buy domain names that you search for online.
It wasn’t exactly clear to me how this was happening until I chanced across this excellent article on my new favorite blog
This is a neat little feature in the new Windows Live Mail.

For those who don’t know, Windows live mail is the Microsoft’s email replacement for Outlook Express 6.
I love this feature so much because now, my email client won’t corrupt my contacts with a ton of useless entries (if you use craigslist a lot you’ll know what I mean).
Its exellent logic, because if I exchange emails with a person a couple of times, then its a pretty good bet that I want that person in my contact list but am too lazy to do it manually. Now Live Mail does it automagically, so you don’t have to … thats called an “intelligent default”. Makes for excellent application design because it “doesn’t make me think”
What would be even better would be the ability to set the threshold number manually.
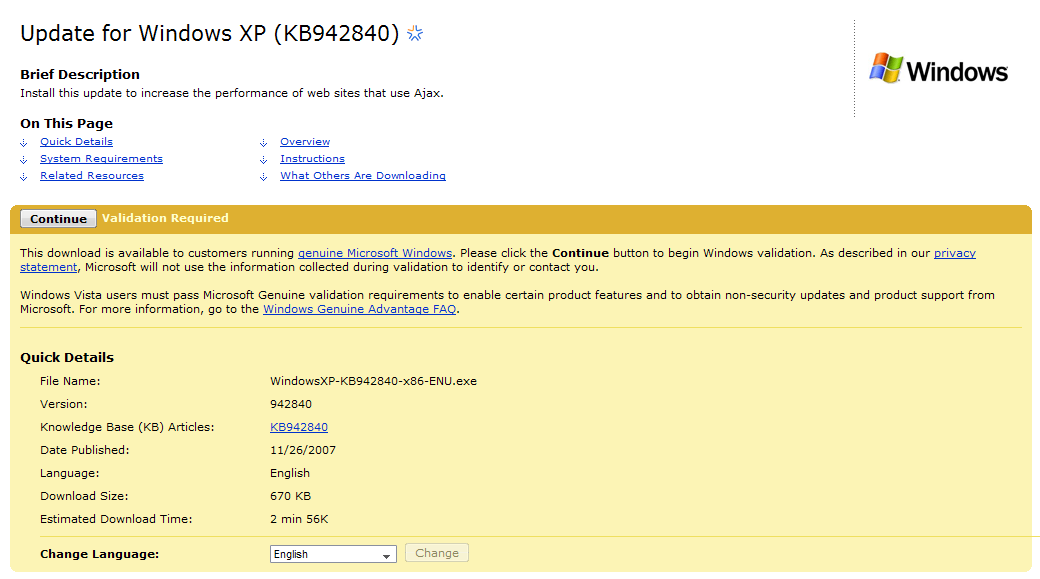
Microsoft just released an update to IE6’s JavaScript engine. It was in response to problems with its (jscript 5.6) garbage collection that would cause poor performance with Large Ajaxy applications … like Gmail. It probably also helps their hotmail web ui too, since that uses ajax as well.
I would personally have liked to see more done with this update (its only a “minor” update), but I suppose you don’t want to give people a reason to hold on to IE 6 right? Hopefully this stops Feed Demon (my RSS reader) from freezing on CNN’s pages?
Read more about the update here