A couple of years ago I worked at a “startup”. I put startup in quotes because it was really a big company pretending to be a small one. Ideas generally flowed from the top down; engineers wound up on the crap end of everything, usually getting overruled and dictated to by PMs and the UX team. Naturally, a lot of the engineers were disillusioned and frustrated with the way things were working.
It was in the middle of this rather cynical time that we got a new PM on the team. He was tasked with improving our onboarding flow and upping conversion numbers, and I was the engineer assigned to work with him on this project.
He had a lot of ideas about how to go about accomplishing this task, and surprisingly, he had actually dug around in the database and pulled some numbers that backed up the direction he was going in (before he came along, very little of what we did was based on data … another source of frustration).
However, on the list of things he wanted to try was something that raised my eyebrow.
“Hey … Pete” (not his real name by the way)
“Hey!”
“Am I reading this right? You want us to leave off the subdomain field on signup?”
“Yes”
“So how will we assign subdomains to the client to access and login to their app?”
“We can just randomly generate a unique string and use that, I think”
“hmmm”
To provide some context, this was 2013, and the subdomain-login-access pattern where a customer was actually a group of people who needed separate logins to access a particular space within an app, had become a mainstay of web apps all over the techie world. The pattern, popularized by 37 Signals and Basecamp almost 8 years earlier, was simply one of those things that everyone just did.
Being the brilliant undiscovered product genius I thought I was at the time, I knew taking away subdomains from the signup form, would be an unqualified disaster. Users would freak out when they signed up and were redirected to random5tring35.app.com to login. They would panic when they couldn’t remember what url to go to login, they would bombard us with emails, and the complaints would force us to roll back this silly change.
I smirked to myself and got to work on getting this and other changes pushed out on the appointed date. After getting everything built out and QA’ed in staging, we rolled out the change and waited …
I’ll spare you the suspense … nobody complained about the subdomains
I was completely blown away. I simply could not understand it … I mean, subdomains were so crucial to the users, how could they not miss that on the sign up?!?!?
Turns out that subdomains are actually confusing for a lot of users, and us taking that off their plate simplified the sign up process. Users mostly didn’t care what the url looked like, and the ones that did, could request a specific one in the settings. (A few years later, 37 Signals would remove subdomains in the newest versions of their apps, citing the exact rationale that we discovered back then)
I learned 2 things that day
– Humble pie is actually pretty delicious, people should eat it more
– You know nothing Jon Snow. (Seriously. You don’t)
Lots of us walk around spouting truisms without any data to support what we’re talking about, and nobody challenges us, so we keep doing the things we’re doing. In reality, if we poke a couple of these “assumptions” we might find that a lot of them come tumbling down like a Jenga tower.
So, whenever you find yourself not wanting to try something because “everyone knows thats how its done”, take a breath then go ahead and test that assumption.
If you’re correct what do you have to fear?

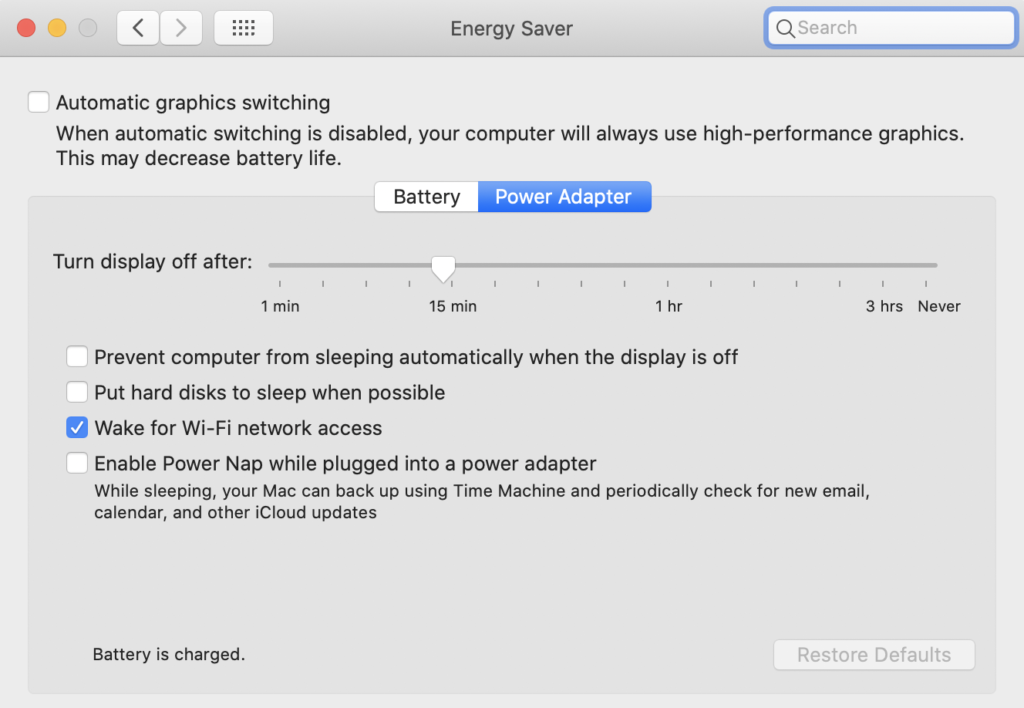 I found that enabling “Automatic Graphics switching” in the Energy Saver section of System preference made the system use up more RAM.
I found that enabling “Automatic Graphics switching” in the Energy Saver section of System preference made the system use up more RAM.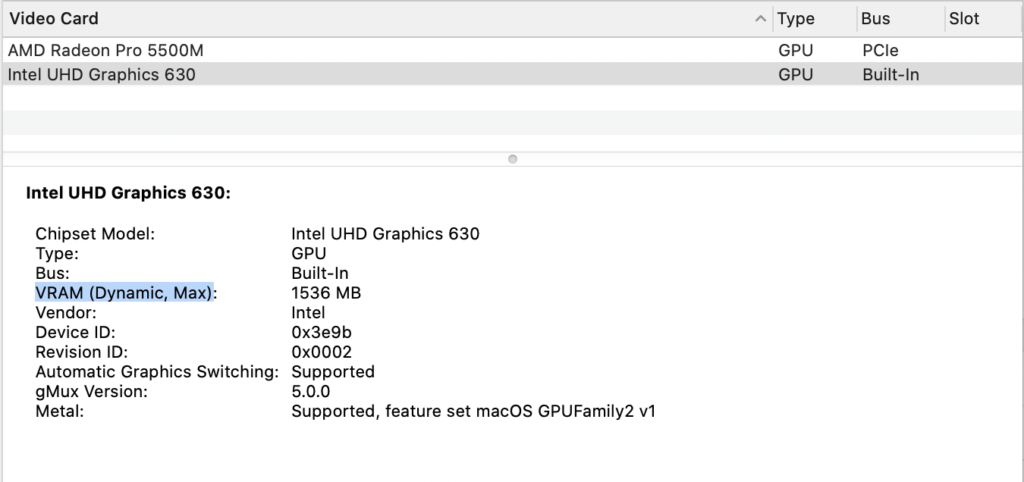 Unfortunately this seemed to put lots of memory pressure on my system after a few days, to where I’d see the occasional crash.
Unfortunately this seemed to put lots of memory pressure on my system after a few days, to where I’d see the occasional crash.