I consider myself a power user of windows xp, so why haven’t I upgraded from winamp 5.35 to winamp 5.52?
After all, every single time I start winamp it bugs me to.
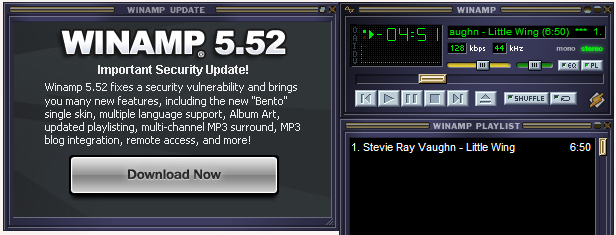
The answer is simple … Its because I’m lazy.
I’m not going to go to winamp.com, try to figure out which version to download and then actually install it over again, just so winamp runs exactly the same as it did before! No way.
But, if the program went out there got the update and installed it for me … I wouldn’t object.
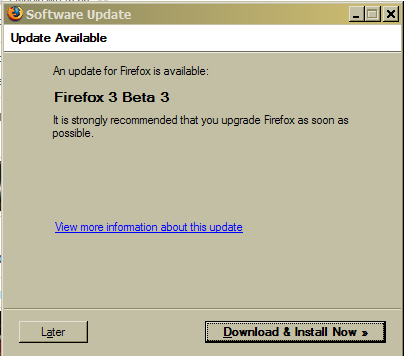
Firefox does this right.
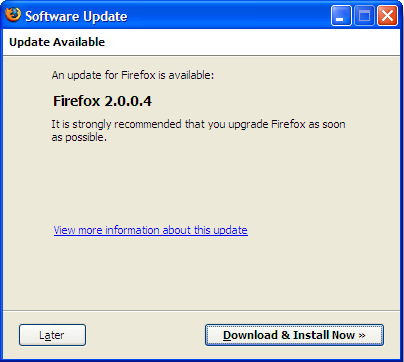
When an update is available, it goes out and finds it for me. If I okay it, it installs the update for me and restarts my browser, putting me back viewing the page I was looking at before … like nothing happened. All I have to do is hit “Download & Install Now”. How easy is that?
Nag screens/prompts/dialogs are very annoying. My natural instinct is to close them and get on with my life.
In that scenario, everybody loses.
So if you write software, you should strive to have it update automatically, if you possibly can. That would definitely be a selling point for me as your customer. (Hear that Blumenthals software?)
PS: Most software (including wordpress) does require you to go download and install the newest versions. Since automatically updating software is so rare it could be a killer feature if you incorporated it into your software.