From a presentation I gave to a bunch of UT Design undergrads in a class taught by my dear friend Terry Soloway.
I was digging through my old stuff and found it, thought I’d throw it up.
Be kind 😀
From a presentation I gave to a bunch of UT Design undergrads in a class taught by my dear friend Terry Soloway.
I was digging through my old stuff and found it, thought I’d throw it up.
Be kind 😀
There’s a story from this one scene in the interminably brilliant movie ‘Traffic‘ which I have never been able to forget (I went and found it on imDb).
You know, when they forced Khruschev out, he sat down and wrote two letters to his successor. He said – “When you get yourself into a situation you can’t get out of, open the first letter, and you’ll be safe. When you get yourself into another situation you can’t get out of, open the second letter”. Well, soon enough, this guy found himself into a tight place, so he opened the first letter. Which said – “Blame everything on me”. So he blames the old man, it worked like a charm. He got himself into a second situation he couldn’t get out of, he opened the second letter. It said – “Sit down, and write two letters”.
I’m not a very funny guy, but everyone I tell that story to, laughs … a lot
Recently, I’ve been thinking about it a lot in relation to software development. A few times in my career, I’ve come across a codebase that I thought was horrible/ridiculous/over-engineered/whatever, and my first reaction as a young developer was to ridicule or berate the the previous developer, loudly.
The funny thing is that it actually worked, initially anyway. The client was usually apologetic and cut me a lot of slack on deadlines and estimates. Then as I started to work on the code, I would begin to see why the developers made some of the decisions that they did. Maybe their pointy haired boss keeps pushing to get things done faster than is realistically possible, forcing the developer to write smelly code just to get done (“I’ll come back and fix it later!”), or there is some bureaucratic technical constraint that forces you to do things that appear very stupid at first glance. Sometimes, even, the developer was more advanced than I was and I couldn’t understand what they had written initially, so I just labeled it ‘overly complex’ because I couldn’t figure it out in one sitting.
The moral of the story is, professional courtesy matters. Always give the person that went before you the same kind of benefit of the doubt that you’d want someone coming after you to have for your work. Badmouthing the code you’re working on, can come back to bite you in the ass when you become its undisputed owner. Be slow to do it, and if you must speak ill of the dead (so to speak), then be respectful, unless they absolutely deserve it (this is rare).
You see, the client/your boss will usually give you the time and resources to fix up the code, so you only get to blame the old guy for so long. Eventually, the question becomes “Why does the code still suck after all this time that you’ve been working on it?”. If you can’t answer that satisfactorily, you might find yourself out of a job, and who knows what the next guy is going to say about you?
Mel’s job was to re-write the blackjack program for the RPC-4000. (Port? What does that mean?) The new computer had a one-plus-one addressing scheme, in which each machine instruction, in addition to the operation code and the address of the needed operand, had a second address that indicated where, on the revolving drum, the next instruction was located. In modern parlance, every single instruction was followed by a GO TO! Put *that* in Pascal’s pipe and smoke it.
Mel loved the RPC-4000 because he could optimize his code: that is, locate instructions on the drum so that just as one finished its job, the next would be just arriving at the “read head” and available for immediate execution. There was a program to do that job, an “optimizing assembler”, but Mel refused to use it.
“You never know where it’s going to put things”, he explained, “so you’d have to use separate constants”.
Click image to go to Announcement page.
Hopefully I’ll get a chance to install it and write a half-decent review soon (for the Ruby/Ruby on Rails part at least)

Regarding my post yesterday about Netbean’s new 6.7 rc releases …
While my initial user experience was dandy, I have since discovered some show stopping bugs.
– When trying to import your plugins from a previous version (6.5 in my case), the screen that pop up mysteriously disables mouse clicks.
So you basically get stuck at a screen like this one …

… with no possible way of moving forward or back.
I had to kill the netbeans process and restart (happened in both rc2 and rc3).
To be fair, after restarting, I had no more problems … the plugins seemed to have imported just fine.
– I also discovered another odd problem while trying to work on migration files in Rails. After Netbeans produced one intellisense dropdown, the entire IDE would start freezing on every 2 or three key strokes … making itself unusable. I had this problem in rc2, no such problem with rc3.
– On the plus side, startup time is *a lot* faster than in 6.5. As soon as I loaded a few modules the startup speed went back to be cell-phone-customer-service slow, so no plus there.
+ The whole netbeans process seems to be self contained now. It used to be that when you looked in process explorer, you’d see Netbeans, nbexec and java, with the real size of netbeans contained in the Java process.
This, happily, is no longer the case. Netbeans still easily tops 200MB of memory though :\
– Trying to create a new rails app, the browse button on this screen does not work, terrible eh?

PS: This worked for Netbeans 6.7 RC2, however it will HORRIBLY break any attempt to use irb from the windows command line
If you right click on a project in Netbeans then go to ‘Ruby Shell (IRB)’, you should get dropped into a ruby IRB window.
Unfortunately for most of you on windows, you might get this instead …

An easy fix is to go to irb.bat and comment out the first 7 lines of code so that it looks like this
#@echo off #@if not "%~d0" == "~d0" goto WinNT #\bin\ruby -x "/bin/irb.bat" %1 %2 %3 %4 %5 %6 %7 %8 %9 #@goto endofruby #:WinNT #"%~dp0ruby" -x "%~f0" %* #@goto endofruby #!/bin/ruby # # irb.rb - intaractive ruby # $Release Version: 0.9.5 $ # $Revision: 11708 $ # $Date: 2007-02-13 08:01:19 +0900 (Tue, 13 Feb 2007) $ # by Keiju ISHITSUKA(keiju@ruby-lang.org) # require "irb" if __FILE__ == $0 IRB.start(__FILE__) else # check -e option if /^-e$/ =~ $0 IRB.start(__FILE__) else IRB.setup(__FILE__) end end __END__ :endofruby |

I’d been using 6.5 for the last couple of months, forgetting to look for updates in my RSS feed, when I came across the announcement of Netbeans 6.7 RC 2.
I quickly downloaded it and started using it, when I found out that RC3 was released just yesterday as well, I’ve downloaded it, but since I’m in the middle of a slew of projects I won’t be installing it until the weekend.
However with RC2, I am impressed that they finally fixed the silly problem of each version of Netbeans not importing settings from previous versions.
The install went smoothly and I was up and running faster than usual.
The things that jumped out at me are
+ There is no annoying subversion connection window that jumps up in the output section for each project that you’re working on any more
– The Ruby irb output window still doesn’t work for me (see screenshot)
– Still no word wrap (I know they’ve said to expect it in version 7.0, but seriously …)
– I spent almost 2 hours yesterday trying to figure out what changed between RC3 and RC2, and I couldn’t do it.
If you can, please drop me a line.
Apparently with each new release, the documentation page updates to the current release. So basically there isn’t a release page for RC2 any longer (please fix this guys).
+ For Ruby on Rails here are the things that are new (nothing exciting really)
Here are the release notes for RC3
Ruby and Rails
enjoy.
I was trying to find out how the NY Giants did last night, so I could incorporate it into a nice little jibe I was going to hurl at a friend of mine, so I went in and typed “NY Giants” … into the search box, to start the ever familiar process of clicking on links and backing up until I found what I wanted.
Guess what came up?

Its like they read my mind! 😀
Funny, but it illustrates *exactly* why Google is kicking everybody’s ass at search.
They write software that anticipates the needs of its users.
You should be asking yourself if your software, business, employees or personal service does the same.
I’m a big fan of the Netbeans IDE, because I love the support it provides for Ruby on Rails.
It means that I upgrade my IDE to the latest release (Milestones, Betas etc) as soon as it comes out, but it also means that with every upgrade, I have to physically go and set every … single … option … again.
Sounds painful doesn’t it?
It is.
Luckily , I found a blog post that describes how to solve this problem and import your netbeans settings from version to version.
This is something that needs to be fixed in Netbeans … that and including a word wrap option … and cakephp support … oops … getting carried away there 😀
I was going through my google analytics logs today and I noticed that a lot of folks were coming to my site on Google searches for stuff like ‘print_r + ruby on rails‘.
So I figured I’d write a blog post about it, because I’ve had the same problem.
What you’re looking for is ‘inspect’.
If you have an array, hash or object that you want to take a quick-and-dirty look at just type in
objectname.inspect
eg:
posts.inspect
or if you’re in rails just do …
render :text => posts.inspect and return false
and you’ll get an output of the contents of said array, hash or object.
Here is a screen capture of a quick irb session to show you how it works.
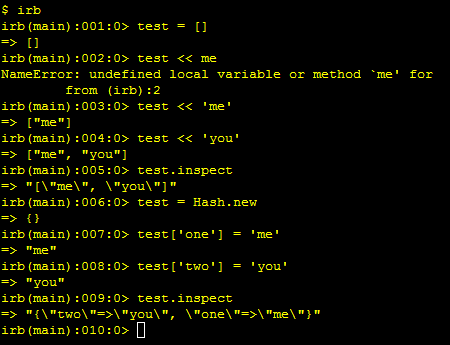
I hope this helps.
The more I work with Ruby and Ruby on Rails, the more I begin to understand (though not necessarily agree with) a lot of the vitriol that has been aimed at PHP over the years by developers using other more rigorous languages.
A few weeks back I ran into this little speed bump while working with Ruby on Rails, where I was trying to do a multiple assignment like this
x = y = z = [] |
Most seasoned Rubyists will be waving their arms around and yelling “NOOOOOO!!!”
But coming from a PHP background this seemed perfectly okay to me.
This one took a little bit but I finally figured it out …
@xml = render_component_as_string :controller => “quote”, :action => “xml”, :params => {:request_id => 100}
This would run the action “xml” of the controller “quote” and pass the parameter “100” to it to do so.
Whatever would have been displayed at /quote/xml/100 is now stored in @xml
This allows you get the output from any action …. anywhere, also allowing you to pass parameters to it in the process.
Even better, this actually runs the action and its view (unlike render :action, which just renders the action view).
For more details, go to the Ruby On Rails Manual > Using components
After weeks of anticipation , the apache module that allows you to upload your ruby on rails application to the server and have it “just work” has just been released.
I’ve just downloaded the source code from their git repository (git rocks!!) and am trying to see if it’ll install on windows.
Update: It won’t install on windows and there are no plans to ever allow it to (damned Linux elitists!!! :P).
I’ve been interested in moving to the new Versioning system championed by none other than Linus Torvalds … creator of Linux.
But I’m on a windows box (and I like it here) and didn’t want to deal with using cygwin to manage repositories in Git.
Cue this succinct blog post on how to run Git on windows.
enjoy.
Thanks for Justin Cook for doing all the leg work on this one.
All you have to do is create a new table from the old one, which filters out the duplicate entries
1 2 3 | CREATE TABLE new_table AS SELECT * FROM old_table WHERE 1 GROUP BY [colum_to_remove_duplicates_from]; |
so as an example
1 2 | CREATE TABLE news_new AS SELECT * FROM news WHERE 1 GROUP BY [title]; <a href="http://www.concept47.com/austin_web_developer_blog/developers/getting-rid-of-duplicate-entries-in-your-mysql-database/#more-113" class="more-link">Continue reading <span class="meta-nav">→</span></a> |